原问题
一个DRMDP(s-rec)可以表示为:
π(⋅∣s)∈Δ(A)sup s.t. Psinfa∈A∑π(a∣s)EPs,a[R(s,a,S)+γv(S)]a∈A∑Df(Ps,a∥Ps,a)≤∣A∣ρPs,a∈Δ(S)for all a∈A
这里我们假设R∈R∣S∣×∣A∣×∣S∣,R(st,at,st+1)由当前时刻的状态,动作和下一时刻的状态决定。
由于目标函数对于Ps和π都是线性的,因此可以应用Sion 极小极大定理来交换极小和极大的顺序。经过交换之后,问题转化为:
Psinf s.t. a∈AmaxEPs,a[R(s,a,S)+γv(S)]a∈A∑Df(Ps,a∥Ps,a)≤∣A∣ρPs,a∈Δ(S)for all a∈A
如何理解经过极大极小定理之后随机策略变为了确定性策略:一个简单的例子
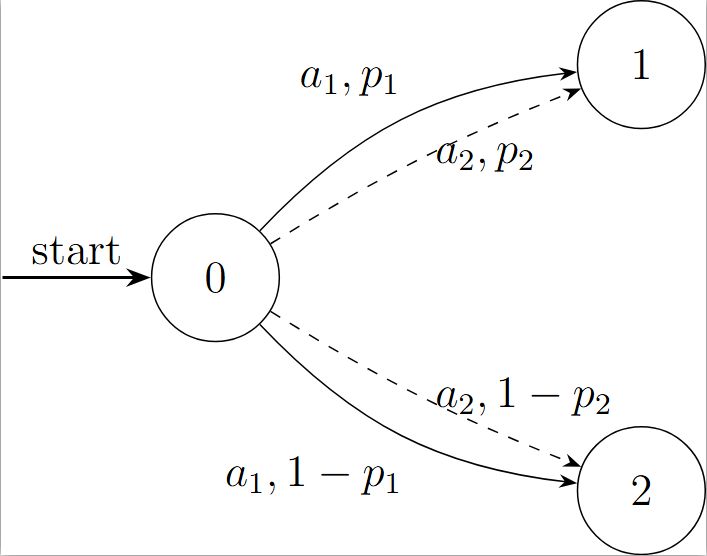
假设我们只考虑一步决策,并且设置奖励函数为 R(⋅,⋅,1)=1 和 R(⋅,⋅,2)=0(只要到达状态1就给1点奖励)。假设动作的概率为 p1=0.8 和 p2=0.6,ρ=0.3,使用L1距离,则原问题可以简化为:
d∈Δ(A)sup s.t. pinfd⊤pa∈A∑∣pa−pa∣≤∣A∣ρpa∈Δ(S)
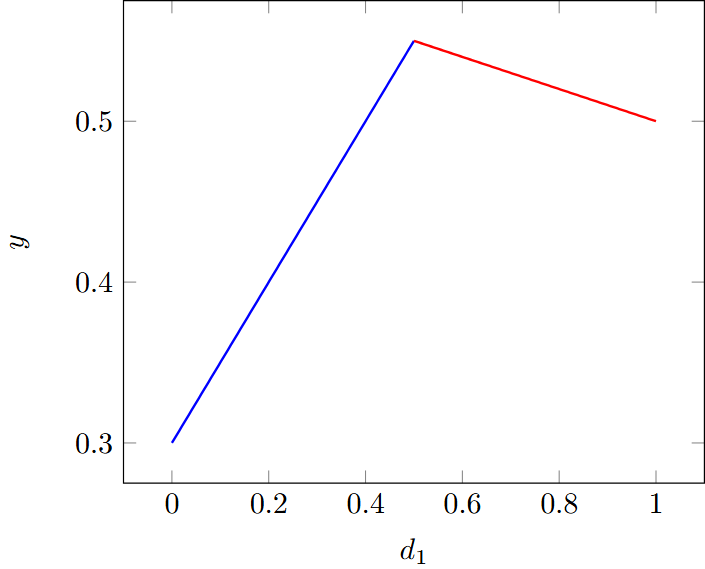
这里的目标是最优化两个概率向量 d 和 p。当 d1≥d2(即 d1≥0.5)时,infp 将会将所有的budget(预算)用于减小 p1,而当 d1<d2(即 d1<0.5)时,infp 会将所有的 budget 用于减小 p2。因此,优化结果可以表达为:
pinfd⊤p={d1p1+d2(p2−0.3)=0.5d1+0.3,d1(p1−0.3)+d2p2=−0.1d1+0.6,d1<0.5d1≥0.5
因此,当 d1=0.5 时取得到最大值。最优的策略为 π∗=[0.5,0.5]。
通过交换极大和极小的顺序,我们可以得到以下问题:
pinf s.t. a∈Amax paa∈A∑∣pa−pa∣≤∣A∣ρpa∈Δ(S)
此时,infp会使p1,p2同样的小,即 p1=0.55(对应的 budget 为 0.5)和 p2=0.55(对应的 budget 为 0.1),总的 budget 为 0.6。
如果不使得p1,p2同样小,比如p1=0.5,p2=0.6,则policy会选择0.6,把p1降低到0.5的budget一定程度上被“浪费了”
最终得到的最优值都是0.55,但π∗在max-min中是[0.5,0.5],而在min-max中是[1,0]或[0,1]。
bisection 算法
Chin Pang Ho, Marek Petrik, Wolfram Wiesemann . Fast Bellman Updates for Robust MDPs. (2018)[pdf]
Recall that,交换完之后的优化问题为:
Psinf s.t. a∈AmaxEPs,a[R(s,a,S)+γv(S)]a∈A∑Df(Ps,a∥Ps,a)≤∣A∣ρPs,a∈Δ(S)for all a∈A
由于此时π是一个确定性策略,π只会选择EPs,a[R(s,a,S)+γv(S)]中最大的一个。因此adversary 要改变Ps来均匀地降低所有动作下的收益(如前面例子中所提到的那样)。令
u=Psinf a∈AmaxEPs,a[R(s,a,S)+γv(S)]
此时Ps∗满足EPs,a[R(s,a,S)+γv(S)]对于所有a均相等。令ξ表示budget大小,定义
qa(ξ)= Ps,a∈Δ(S)infs.t. EPs,a[R(s,a,S)+γv(S)] Df(Ps,a∥Ps,a)≤ξa
随着ξ增加,qa(ξ)会减小。下图是一个示例,假设我们有3个动作,adversary需要将每个qa都调整到恰好等于u(ξa=0时比u小的就不用调了),则用到的全部预算为ξ1+ξ2+ξ3。
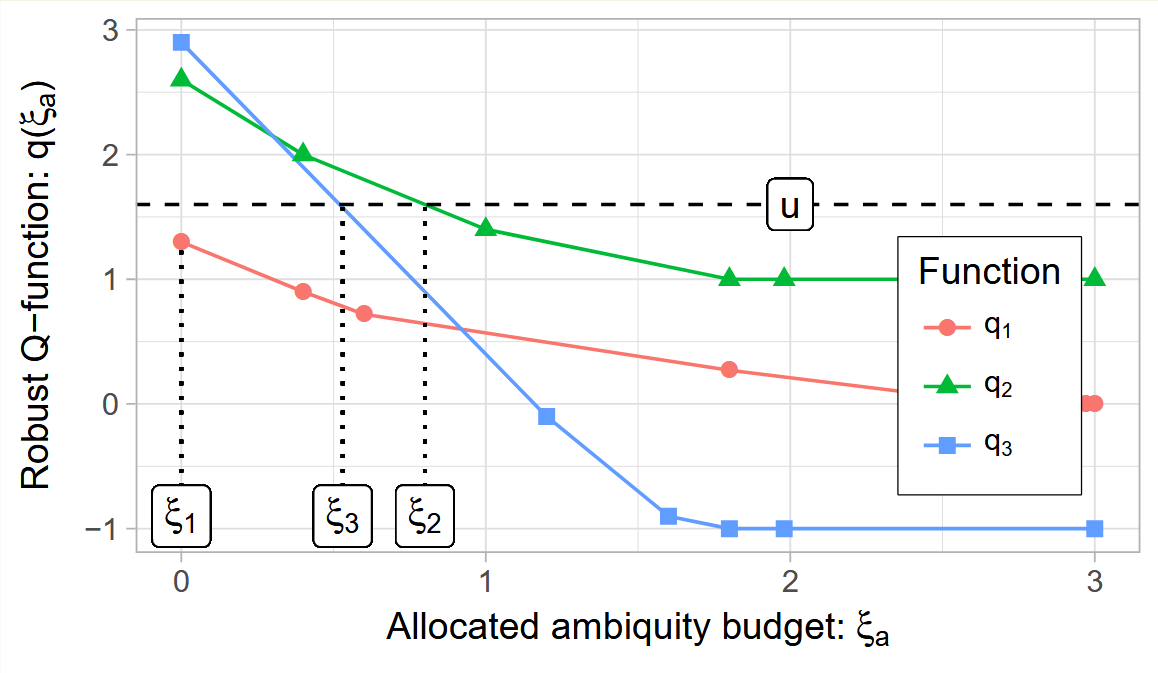
经过以上过程,如果我们知道每个动作的ξa,我们就可以算出qa(ξa),从而算出u。但我们需要的是从∑a∈Aqa(ξa)≤∣A∣ρ以及最优值所有qa(ξa)都相等算出u。
bisection的思路就是二分法选择u的值,然后检测∑aξa是否满足约束条件。如果∑aξa>∣A∣ρ,则表明u小了,反之u大了。剩下的问题就是我们不知道给定u,ξa是多少,所以我们要求u=qs,a(ξa)的反函数ξa=qs,a−1(u):
Ps,amin s.t. Df(Ps,a∥Ps,a)EPs,a[R(s,a,S)+γv(S)]≤uPs,a∈Δ(S)for all a∈A
qs,a−1(u)的对偶问题
Ho, Chin Pang, Marek Petrik, and Wolfram Wiesemann. Robust $\phi $-Divergence MDPs. (2022) [pdf]
由于以上问题解决起来还是比较困难,所以我们继续求上述问题的对偶问题。这里先直接给出对偶问题的形式:
λ∈R+,ν∈Rmax −λu+ν−EPs,a[f∗(−λ(R(s,a,S)+γv(S))+ν)]
KL
令ws,a(S)=R(s,a,S)+γv(S),ws,a,min=minPs,a≥0ws,a,由于求解过程中,λ可能趋于0所以会出现指数爆炸的数值问题,因此需要用数值稳定版本进行求解。
对于KL散度,对偶问题为:
λ∈R+maxf(λ)=λ∈R+max−λu−logEPs,a[e−λws,a].
robust version
λ∈R+max−λu−logEPs,ae−λ(ws,a−ws,a,min)+λws,a,min
梯度为:
∂λ∂f=−u+EPs,a[e−λws,a]EPs,a[ws,a⋅e−λws,a]
robust version
∂λ∂f=−u+EPs,a[e−λ(ws,a−ws,a,min)]EPs,a[ws,a⋅e−λ(ws,a−ws,a,min)]
注意到
λ∈[0,log(minPs,a1)⋅u−minw1]
又由于f是个凹函数,因此可以用二分法来寻找最大值,如果梯度大于0,则表明λ∗在右侧,反正则在左侧。
proof
λmax=log(minPs,a1)⋅u−minw1⟺Ps,a,min⋅exp(λmax(u−wmin))=1⟹s′∈S∑Ps,a(s′)⋅exp(λmax(u−w(s′)))≥1⟺s′∈S∑Ps,a(s′)⋅exp(−λmaxw(s′))≥exp(−λmaxu)⟺log(s′∈S∑Ps,a(s′)⋅exp(−λmaxw(s′)))≥−λmaxu⟺f(λmax)≤0
由于f是个凹函数,f先增后减且f(0)=0,所以f(λmax)≤0表明λmax>λ∗。
policy
在求解出v∗之后,还要反过来求解policy。我们通过对偶问题来求解policy。由于投影到R+和Δ(⋅)都比较方便,所以可以使用投影梯度法。分别计算对λ和da≡π(a∣s)的梯度。
π∈Δ(A),λ≥0sup(−λ∣A∣ρ−a∈A∑λlogEPs,a[exp(−λπ(a∣s)(R(s,a,S)+γv(S)))])
∂λ∂f=−∣A∣ρ−a∈A∑[logEPs,a[e−daws,a/λ]+λ1EPs,a[e−daws,a/λ]EPs,a[daws,ae−daws,a/λ]].
robust version
∂λ∂f=−∣A∣ρ−a∈A∑[logEPs,a[e−da(ws,a−ws,a,min)/λ]−λdaws,a,min+λ1EPs,a[e−da(ws,a−ws,a,min)/λ]EPs,a[daws,ae−da(ws,a−ws,a,min)/λ]].=−∣A∣ρ−a∈A∑[logEPs,a[e−da(ws,a−ws,a,min)/λ]+λ1EPs,a[e−da(ws,a−ws,a,min)/λ]EPs,a[da(ws,a−ws,a,min)⋅e−da(ws,a−ws,a,min)/λ]].
∂da∂f=EPs,a[e−daws,a/λ]EPs,a[ws,ae−daws,a/λ]
robust version
∂da∂f=EPs,a[e−da(ws,a−ws,a,min)/λ]EPs,a[ws,ae−da(ws,a−ws,a,min)/λ]
投影到单纯形上:
Projection onto the simplex code
Yunmei Chen and Xiaojing Ye, Projection Onto A Simplex
其它:sa-rec求解方法
Qt+1(s,a)=Df(Ps,a∥Ps,a)≤ρinf EPs,a[R(s,a,S)+γvt(S)].
对偶问题
λ⩾0sup−λlogEPs,a[exp(−λR(s,a,S)+γv(S))]−λρ.
同样地,令ws,a(S)=R(s,a,S)+γv(S),ws,a,min=minPs,a≥0ws,a,
robust version
λ⩾0sup−λlogEPs,a[e−(ws,a−ws,a,min)/λ]+ws,a,min−λρ.
求导
∂λ∂f=−ρ−[logEPs,a[e−ws,a/λ]+λ1EPs,a[e−ws,a/λ]EPs,a[ws,ae−ws,a/λ]]
robust version
∂λ∂L=−ρ−[logEPs,ae−(ws,a−ws,a,min)/λ−λws,a,min]−λ1EPs,a[e−(ws,a−ws,a,min)/λ]EPs,a[ws,ae−(ws,a−ws,a,min)/λ]
当λ→0
f(λ)=Ps,a(s′)>0minRs,a(s′)+γv(s′)
dλdf=−ρ−[logPs,a(smin)−λminws,a+λminws,a]=−ρ−logPs,a(smin)
由于
λ∗∈[0,ρ(1−γ)1]
因此类似地,可以使用二分法求解