Spark
Motivation
- Hadoop是一个比较基础的语言,需要一个高级语言
- Hadoop每次map/map+reduce之后需要将数据存储到hdfs中,io开销过大
- 此外,spark还支持更多复杂的、多步骤的数据处理(如机器学习)以及实时流数据分析
RDD
RDD,全称为Resilient Distributed Dataset(弹性分布式数据集),是Spark中的一个非常重要的概念。RDD具有以下几个关键特性:
- 不可变性(Immutability):RDD是不可变的,一旦创建便不能更改。
- 分区(Partitioned):RDD是分区的,数据存储在多个分区中以实现并行处理。
- 延迟计算(Lazy Evaluation):RDD的转换操作是延迟执行的,只有当执行Action操作时,才会触发实际的计算。
- 依赖关系(Lineage):Spark通过记录RDD的依赖关系的方式来跟踪其生成过程,当数据丢失时可以通过血统重新计算丢失的分区。
RDD是
- Set of Partitions(分区集合)
- List of Dependencies on Parent RDDs:RDD 是通过转换操作(如 map、filter 等)从其他 RDD 生成的,每个 RDD 记录了它从哪些父 RDD(Parent RDDs)派生而来,这种关系称为依赖关系(Dependencies)
- Function to Compute a Partition Given Its Parents:每个 RDD 都定义了一个函数,用于计算其分区的数据。这个函数通过依赖关系从父 RDD 的分区中获取数据,并进行操作(如 map、filter 等)
- ** (Optional) Partitioner**
- (Optional) Preferred Locations for Each Partition:RDD 可以指定每个分区的优选位置(Preferred Locations),即分区的最佳计算节点。这通常用于数据本地化(Data Locality)。
RDD的操作可以分为两类:
- 转换操作(Transformations):如
map、flatMap、reduceByKey等,这些操作定义了RDD的转换逻辑,但不会立即执行。 - 行动操作(Actions):如
reduce、saveAsTextFile等,这些操作会触发实际的计算。
operation可以分为以下几类:
- Map-like operations
- Reduce-like operations
- Sort operations
- Join-like operations
- Set-ish operations
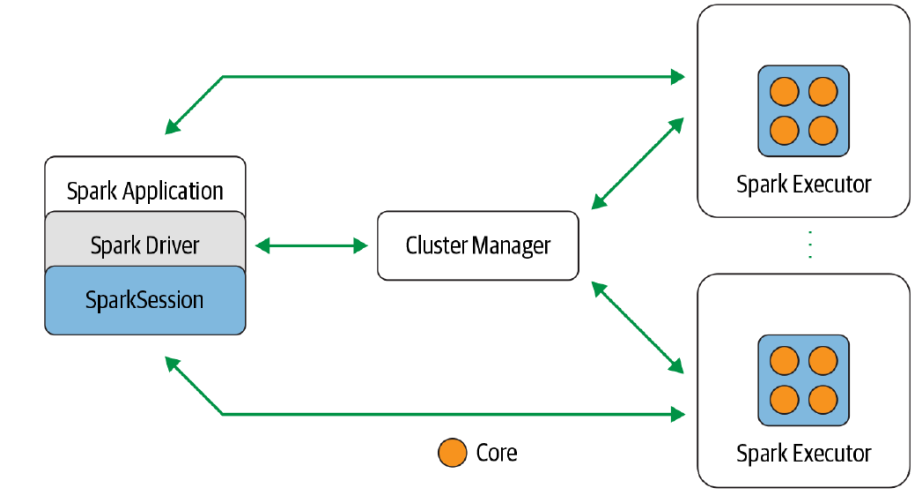
Spark结构
与MapReduce类似,spark需要一个driver与cluster manager(类似NameNode)进行通信,每个机器上有一个spark executor用于执行程序。
Spark Application是一个基于Spark API构建的用户程序,用于在Spark集群或环境中运行
Spark Driver是Spark Application的核心组件,提供接口和API以供应用程序使用
Spark Session是与Spark互动的入口点,它提供了一个统一的接口来访问所有底层的Spark功能
Spark lazy evaluation
Transformation不会进行计算,直到action
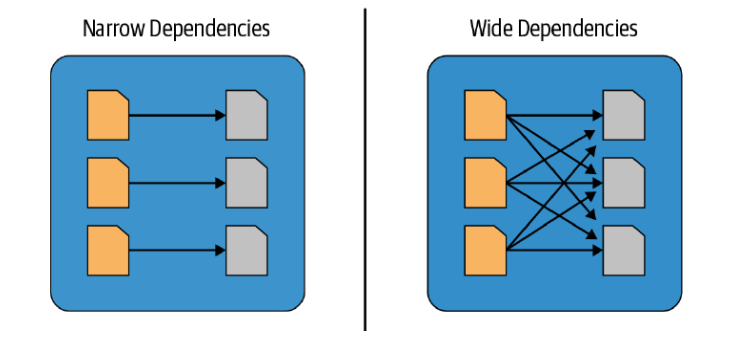
如果有多个都是narrow dependencies,那么可以把这些合并成一个phase,pipeline方式运行,直到有wide dependencies.
schedule optimization
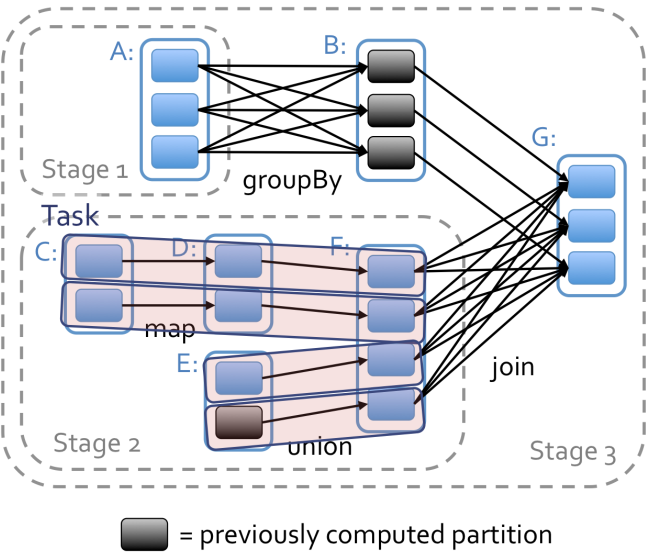
根据wide dependency划分stage,narrow dependency部分可以使用pipline进行加速。
hash shuffle
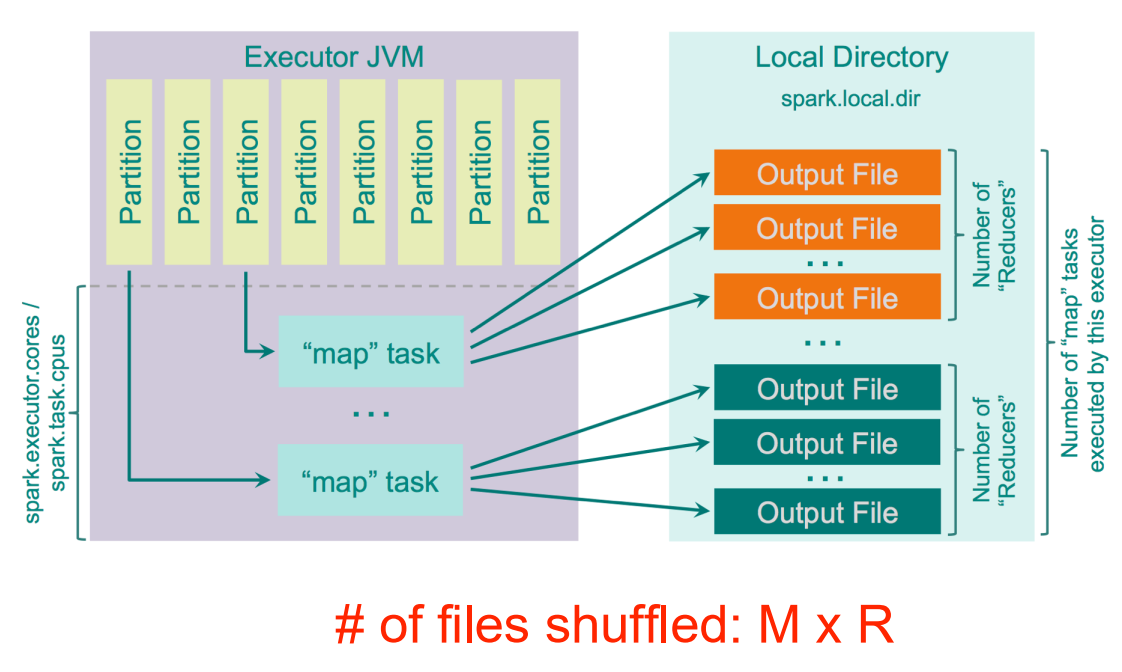
每个mapper会根据hash生成R(reducer)数量个output file
Lineage
word RDD:
1 | text_file = sc.textFile(“hdfs://...”) |
dependencies: one-to-one
join RDD
1 | rdd1 = sc.parallelize([(“foo”, 1), (“bar”, 2), (“baz”, 3)]) |
dependencies: all-to-all
pySpark
初始化实例
1 | from pyspark import SparkContext, SparkConf |
SparkConf:用于配置Spark应用程序的参数(如应用名称、运行模式等)。SparkContext:Spark功能的入口点,负责与集群通信、创建RDD(弹性分布式数据集)等。.setAppName(""):设置应用程序的名称(在Spark UI和日志中显示)。.setMaster("local[*]"):指定运行模式为本地模式(local),[*]表示使用所有可用的CPU核心
读取文件
sc.textFile用于从文件系统(如本地文件系统、HDFS、S3等)读取文本文件,并将其转换为一个RDD
查看rdd相关信息
rdd.count():返回 RDD 中元素的总数
rdd.first():返回 RDD 的第一个元素
rdd.collect():返回一个包含所有元素的列表
rdd.getNumPartitions():返回 RDD 的分区数量
rdd.glom():将每个分区的数据以列表的形式返回
tranformation
map like
rdd.filter(f):对 RDD 的每个元素应用函数 f,保留函数返回 True 的元素,过滤掉返回 False 的元素
1 | rdd = sc.parallelize([1, 2, 3, 4, 5]) |
rdd.map(f):对 RDD 的每个元素应用函数 f,将函数返回值作为新 RDD 的元素。
1 | rdd = sc.parallelize([1, 2, 3, 4, 5]) |
rdd.flatMap(f)

map是one-to-one mapping
flatMap是 one-to-many mapping
rdd.distinct():去除重复的元素
1 | rdd = sc.parallelize([1, 2, 2, 3, 4, 4, 5]) |
rdd1.union(rdd2):返回两个 RDD 的并集,将两个 RDD 的所有元素组合到一个 RDD 中
1 | rdd1 = sc.parallelize([1, 2, 3]) |
rdd1.cartesian(rdd2): 返回两个 RDD 的笛卡尔积
1 | rdd1 = sc.parallelize([1, 2]) |
rdd1.zip(rdd2):将两个 RDD 按位置进行配对将两个 RDD 按位置进行配对(要求两个 RDD 的长度相同,否则会报错)
1 | rdd1 = sc.parallelize([1, 2, 3]) |
rdd.zipWithIndex():将 RDD 的每个元素与其索引(从 0 开始)配对,返回一个新的 RDD,每个元素是 (element, index) 的二元组
1 | rdd = sc.parallelize(["a", "b", "c"]) |
rdd.zipWithUniqueId():将 RDD 的每个元素与一个唯一 ID 配对,返回一个新的 RDD,每个元素是 (element, unique_id) 的二元组。(Items in the kth partition will get ids k, n+k, 2*n+k, …, where n is the number of partitions.)
1 | rdd = sc.parallelize(["a", "b", "c", "d", "e"], numSlices=2) |
reduce like
rdd.reduceByKey(func):对元素为 (key, value) 形式的 RDD,根据 key 进行分组,并用函数 func 对每组的 value 进行聚合,返回一个新的 (key, reduced_value) 形式的 RDD。
1 | rdd = sc.parallelize([('a', 1), ('b', 2), ('a', 3), ('b', 4)]) |
rdd.sortByKey([ascending=True]):对元素为 (key, value) 形式的 RDD,按照 key 进行排序,返回排序后的新 RDD。
1 | rdd = sc.parallelize([('b', 2), ('a', 1), ('c', 3)]) |
rdd.groupByKey():对元素为 (key, value) 形式的 RDD,根据 key 进行分组,把相同 key 的所有 value 收集到一起,返回新的 RDD,每个元素形式为 (key, Iterable[value])。
1 | rdd = sc.parallelize([('a', 1), ('b', 2), ('a', 3), ('b', 4)]) |
rdd1.intersection(rdd2):返回两个 RDD 的交集
1 | rdd1 = sc.parallelize([1, 2, 3]) |
rdd1.substract(rdd2):返回一个新的 RDD,该 RDD 包含 rdd1 中所有不在 rdd2 中的元素(即 rdd1 减去 rdd2)
1 | rdd1 = sc.parallelize([1, 2, 3, 4, 5]) |
Actions
reduce 是 Spark RDD 的一种 聚合(Aggregation)操作,用于将整个 RDD 的所有元素使用给定的函数聚合成一个最终结果
1 | rdd = sc.parallelize([1, 2, 3, 4, 5]) |
aggregate(zeroValue, seqOp, combOp):zeroValue:初始值。seqOp:分区内的聚合函数。combOp:各分区间合并结果的聚合函数。
1 | rdd = sc.parallelize([1, 2, 3, 2, 4, 1, 5], numSlices=3) |
fold(zeroValue, func): aggregate 的简化版,两步合并使用同样的函数
1 | rdd = sc.parallelize([1, 2, 3]) |
broadcast
Accumulator 是 Spark 中的一种共享变量,主要用于聚合信息,如计数、求和等。它们只支持添加操作,在 worker 端进行累加,driver 端可以读取最终结果。常见于采集调试信息、统计日志条数、总数等。任务失败后可能会重复累加,所以 accumulator 一般只用于监控、调试,不建议用作业务结果。
1 | acc = sc.accumulator(0) |
Broadcast 用于在分布式计算中高效地向所有 worker 节点分发只读数据(如大字典、配置参数、查找表等),避免每个 task 都拷贝一份,节省内存、网络和带宽。
1 | broadcasts = sc.broadcast([1, 2, 3]) |
Example: find prime numbers
使用的方法是减去合数的方法。对于比如说要找[1,100]之间的所有质数,先求出这区间所有的合数,然后再用所有数的集合和合数的集合相减,得到质数。
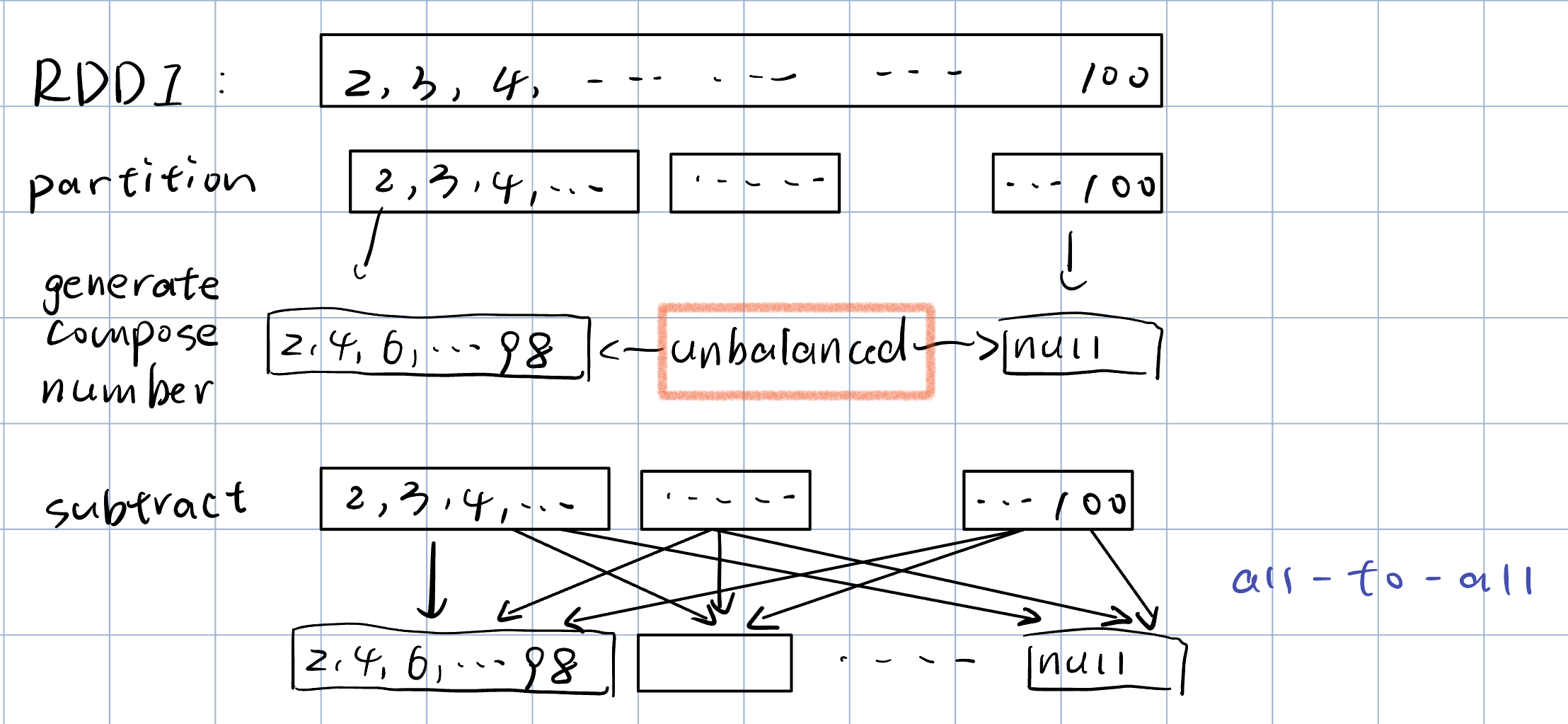
1 | from pyspark import SparkContext |
without partition
1 | Partition 0: 203 : [4, 6, 8, ..., 100, |
with partition:
1 | Partition 0: 30 : [39, ..., 90] |
result
1 | [[], [17, 97], [2], [3, 19, 67, 83], [], [5, 37, 53], [], [7, 23, 71], [], [41, 73, 89], [], [11, 43, 59], [], [13, 29, 61], [], [31, 47, 79]] |
这里结果分区是按照x mod num_partition来分区的。
all_numbers.subtract(composite_numbers)默认使用defaultPartitioner决定结果RDD的分区数。
defaultPartitioner的规则为:取spark.default.parallelism值与父RDD最大分区数中的较大者。本机有16核, 所以分成了16个partition。
如果将
spark.default.parallelism设置为更小或更大的数,比如12或20可以观察到分区的变化
2
3
[[], [41, 61], [2], [3, 23, 43, 83], [], [5], [], [7, 47, 67], [], [29, 89], [], [11, 31, 71], [], [13, 53, 73], [], [], [], [17, 37, 97], [], [19, 59, 79]]
Partition
properties of partition
- Partition不会跨机器,一个Partition只会在一台机子上
- 每台机器可能包含一个或多个Partition(比如有多核)
- 用多少Partition是可以配置的,默认等于核心数量
如果一个transformation操作是在key-value pair上完成的且是窄依赖(mapValues,flatMapValues,filter,filterByKey),如果parent RDD有partitioner,那么一般会自动继承。但是像map,flatmap之类的不会,因为这些会改变key value pairs.
对于reduce like operator,会生成新的partitioner,例如sortByKey一般默认使用RangePartitioner而groupByKey默认使用HashPartitioner(这主要是因为sortByKey的结果是有序的)。
Example: Hash Partitioner and Range Partitioner
首先我们创建一组数据,并观察其partitioner和partition
1 | sc = SparkContext("local", "Partitioner Example") |
partitioner不是必须的。partitioner 只对 Key-Value 形式(Pair RDD)起作用,不适用于普通的仅值(value)RDD。
在一开始的这个数据中,没有key value pair,所以没有partitioner,但是partition是有的,这个partition是Spark框架自动分配的以保证work balance
然后我们进行一次map操作,再观察partitioner和partition
1 | rdd = rdd.map(lambda t: (t[0], t[1] + 1)) |
原因同上。最后我们进行一次reduceByKey
1 | rdd = rdd.reduceByKey(lambda x, y: x + y) |
可以看到,进行reduceByKey后,出现了partitioner,默认使用的是hash function作为partitioner
Range Partitioner
1 | rdd1 = rdd.map(lambda x: (x[0], x[1] + 1)) |
注意到经过map之后partitioner就无了
1 | rdd2 = rdd.mapValues(lambda x: x + 1) |
但是如果是mapValues的话就还在,并且根据地址,是其parent的partition function
1 | rdd = rdd.sortByKey() |
可以看到经过RangePartition之后是按顺序排列的
1 | rdd3 = rdd.mapValues(lambda x: x + 1) |
再次经过mapValues,发现partitionFunc依然继承了parent rdd(RangePartitioner)
Example: custom partitioner
1 | data1 = list(range(0, n, 16)) + list(range(0, n, 16)) |
1 | #这个函数的作用是生成每个partition中元素的数量 |
1 | rdd1 = sc.parallelize(zip(data1, data2), 16) |
1 | def f(x): |
可以看到,mod 17 余数为0的和余数为16的元素共享了第一个partition,而最后一个partition 是mod 17 余数为15的。
Example: narrow depencency
一些narrw dependency 的例子:
map操作不会改变partition
1 | # -*- coding: utf-8 -*- |
union不会改变partition
1 | # UNION |
使用partitionby预先分区,就可以在join的时候变成窄依赖
1 | rdd1 = sc.parallelize([(1, "A"), (2, "B"), (3, "C")], 3) |
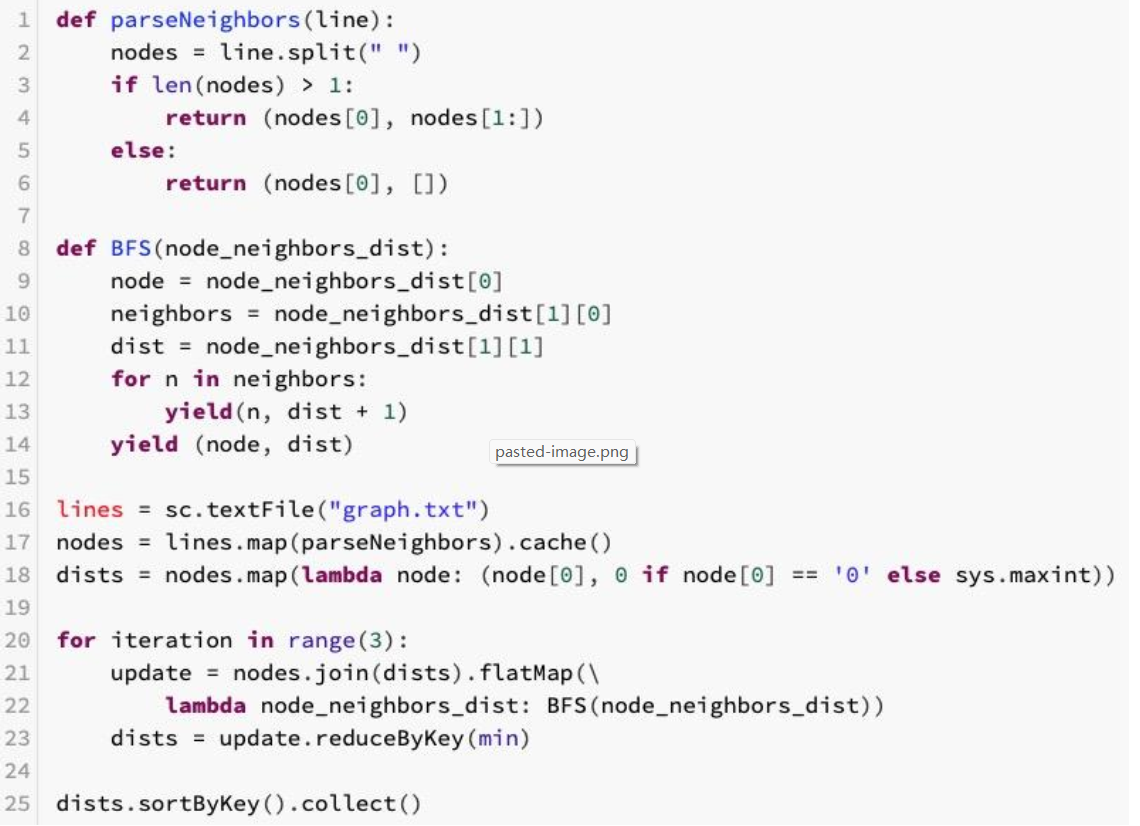
Graph Algorithm
Page Rank

BFS