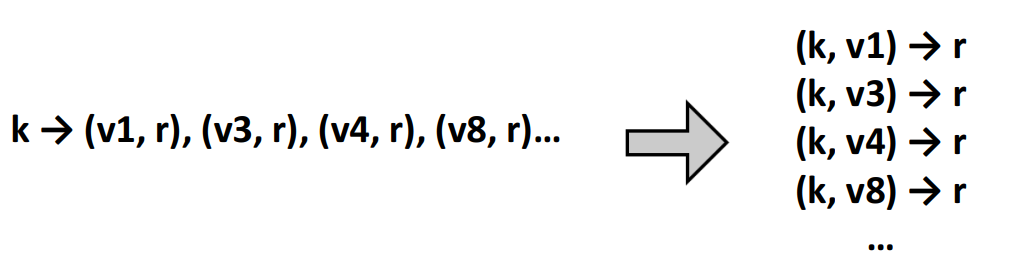MapReduce
基本概念
MapReduce
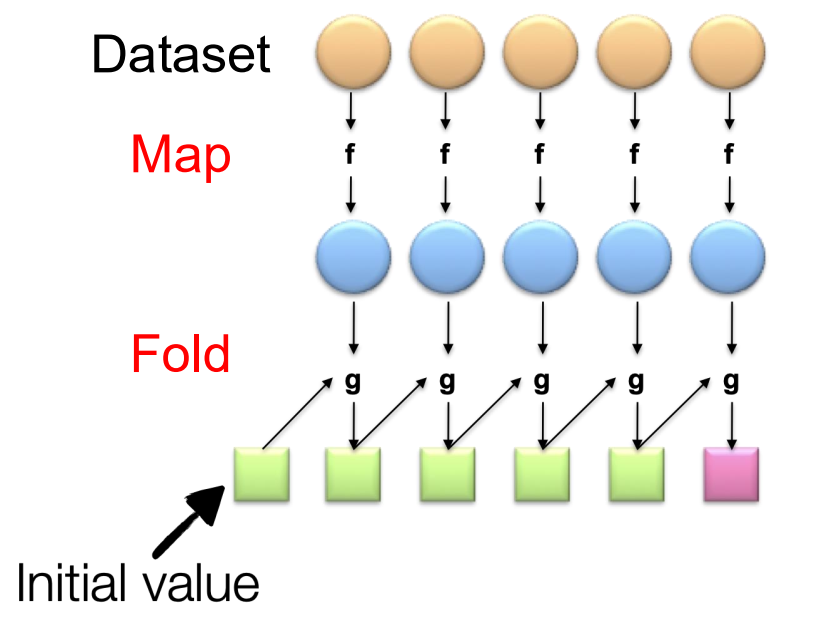
MapReduce借用functional programming概念,map阶段将一部分data作为输入,通过map函数得到输出,在reduce阶段一步一步聚合Map阶段的输出。
[!NOTE]
这里需要满足交换律(commutativity)和结合律(Associativity),否则输出顺序会影响结果。
具体而言,
- 在map阶段
- 在reduce阶段。
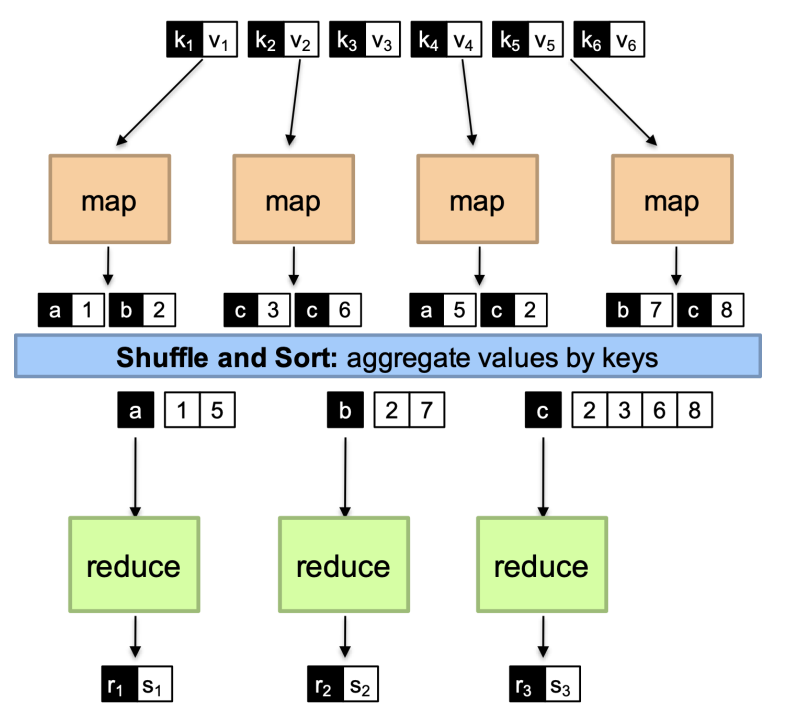
就是说,map阶段接收一个的输入,生成若干键值对,在reduce阶段,将所有具有相同的键的值聚合到一起,然后生成最终结果。
[!IMPORTANT]
所有具有相同key的键值对会被送到同一个reducer
Example
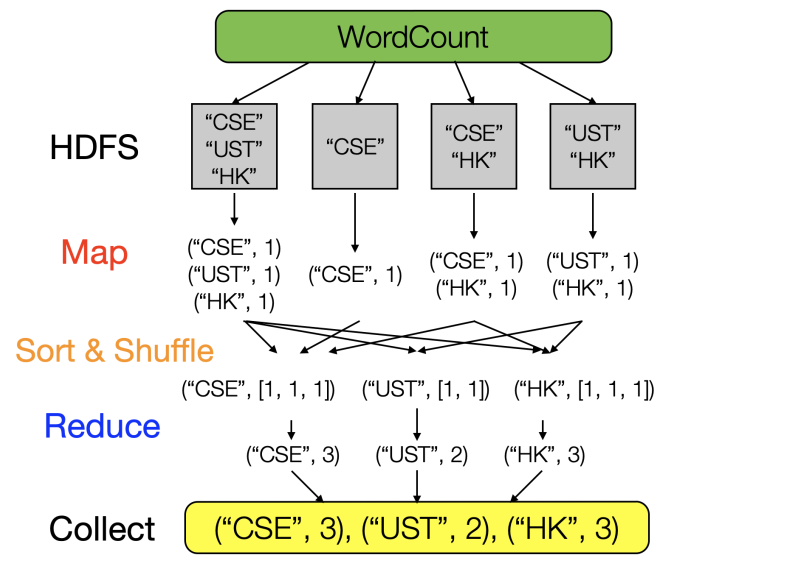
word count
[!NOTE]
2
3
4
5
6
('line 1', 'hello') -> ('hello', 1)
('line 2', 'hello world') -> [('hello', 1), ('world', 1)]
# (k2,[v2]) -> [<k3,v3>]
('hello', [1,1]) -> ('hello', 2)
('world', [1]) -> ('world', 1)
reverse DAG example
将一个有向图的所有方向变成反向
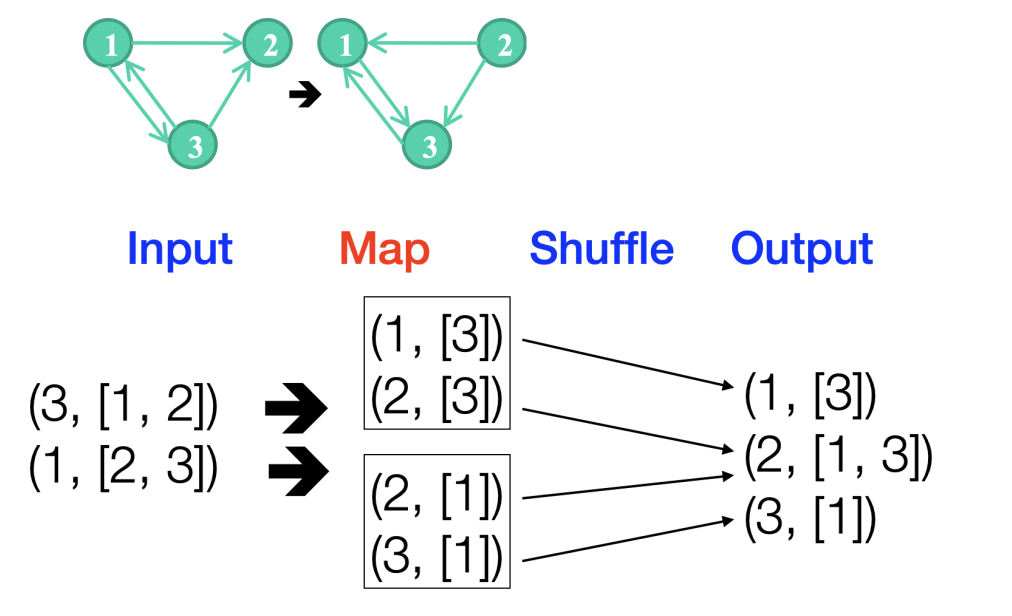
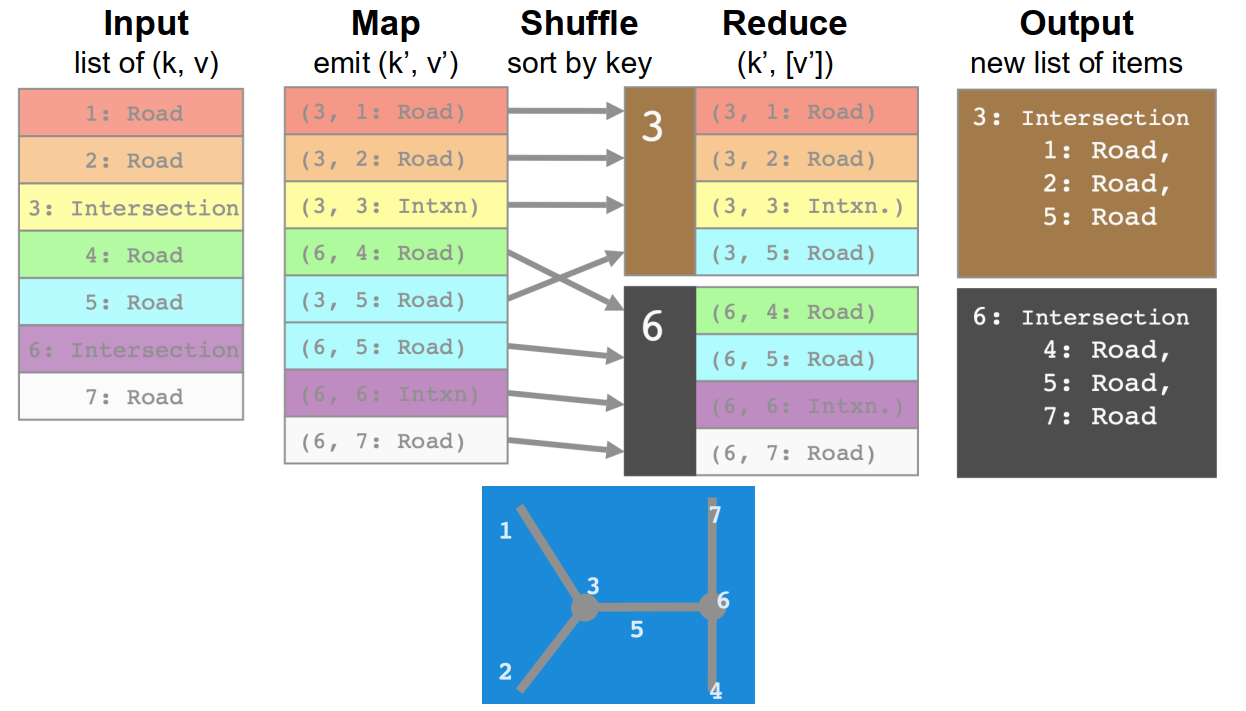
road-intersection example
1 | #原本数据是 |
Combiner & Partitioner
Combiner
在map阶段提前聚合以减少数据传输:,得到的是一个中间结果
1 | ('line 1', 'hello hello') -> ('hello', 1) ('hello', 1) -> ('hello', [1,1]) |
Partition
决定将哪些key送到同一个reducer:
其它
哪些事情是由框架处理的
-
任务调度(scheduling):如分配计算资源(哪些节点要执行哪些操作),均衡负载
-
数据分布(data distribution):将计算移动到数据对应的节点上,自动并行
-
同步(synchronization):Gathers, sorts, and shuffles intermediate data;优化网络和硬盘数据传输
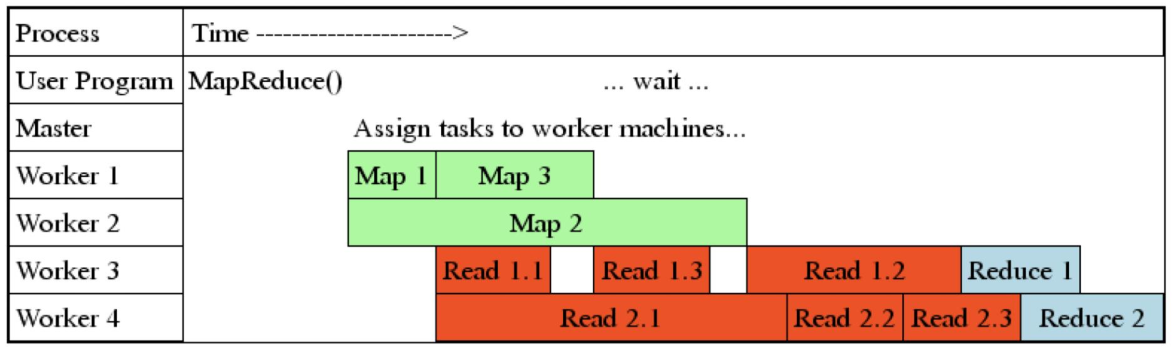
虽然reduce需要等待所有map结束之后才能开始,但是每个map结束之后就可以开始传数据到reducer上了。比如map1 生成了(‘hello’, 1), (‘word’, 1),然后比如我知道hello要去reduce1, word要去reduce2,那么就可以先把这些数据传过去而无需等待map2和map3
sorting: 在每个reducer中,key是排好序的,但v的顺序是任意的
-
errors and faults:detects worker failures and restarts
程序员能控制的和不能控制的
不能控制的:
- mapper和reducer在哪个节点运行
- mapper和reducer开始和结束的时间
- 某个mapper处理哪部分数据
- 哪个键去到哪个reducer
MapReduce流程
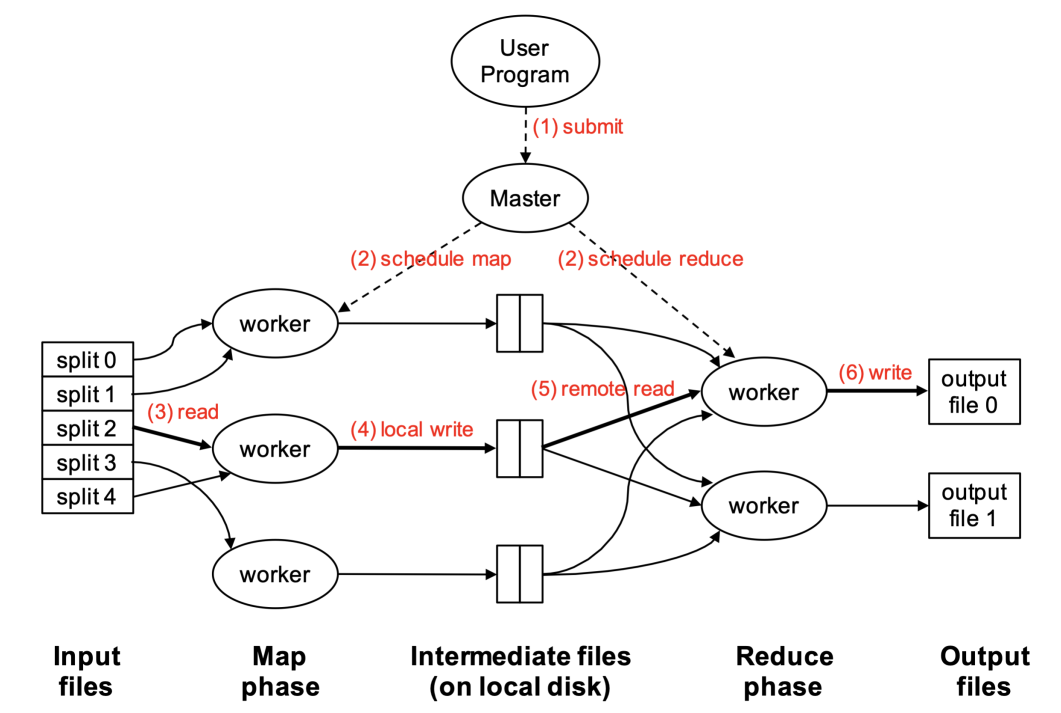
Hadoop
相关概念
job
a packaged Hadoop program for submission to cluster
对于job,需要定义以下内容:
- specify input and output paths
- specify input and output formats
- specify mapper, reducer, combiner, partitioner
- specify intermediate/final key/value classes
- specify number of reducers (but not mappers)
Task: an execution of a mapper or a reducer on a slice of data (job的一个子任务)
Task attempt: a particular instance of an attempt to execute a task on a machine(每个task至少会attempt一次,因为要跑完所有数据,如果task中间失败了,会继续尝试,就会有多个task attampt)
example:
在20个文件上运行word count 是一个job
20个文件会产生20个map task和若干个reduce task
至少会有20个map task attempt
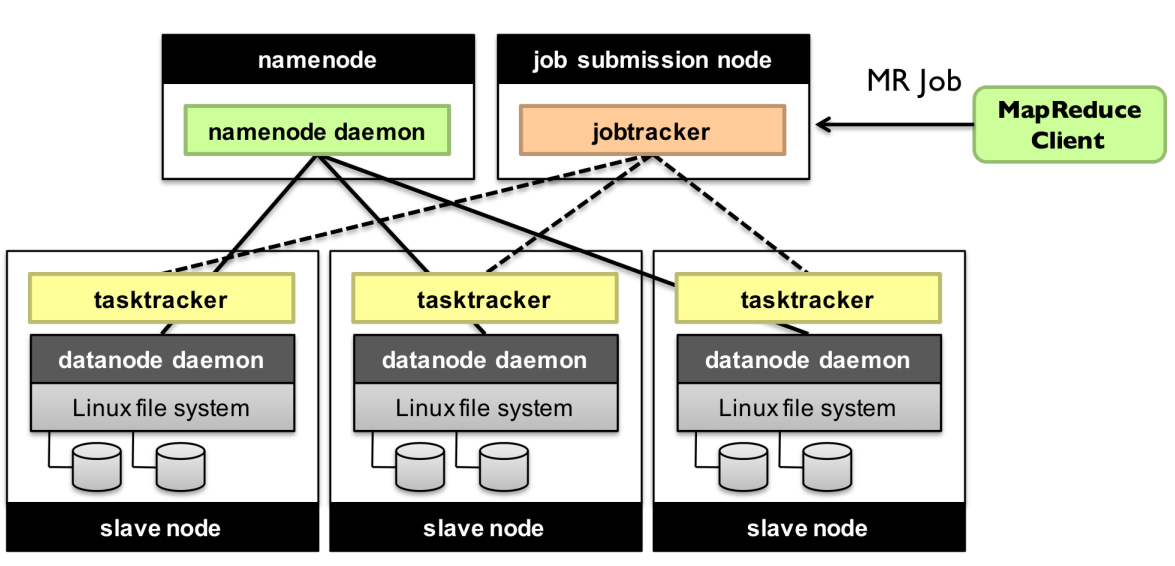
组件
对每个集群有:
NameNode: master node for HDFS
JobTracker: master node for job submission
对每个节点有:
DataNode: serves HDFS data blocks
- DataNode会储存block的metadata,例如CRC校验码
- DataNode每3s会向NameNode 报“heartbeat”
- DataNode每个小时会告诉NameNode当前存在的所有block
TaskTracker: contains multiple task slots
design assumptions
- Cheap, commodity machines
- A “modest” number of very large files (a few million files each > 100MB )
- Batch processing
- Files are write-once, mostly appended to (perhaps concurrently)
- Streaming reads, rather than random data access
- High sustained throughput favored over low latency (高吞吐量而非低延迟)
HDFS Architecture
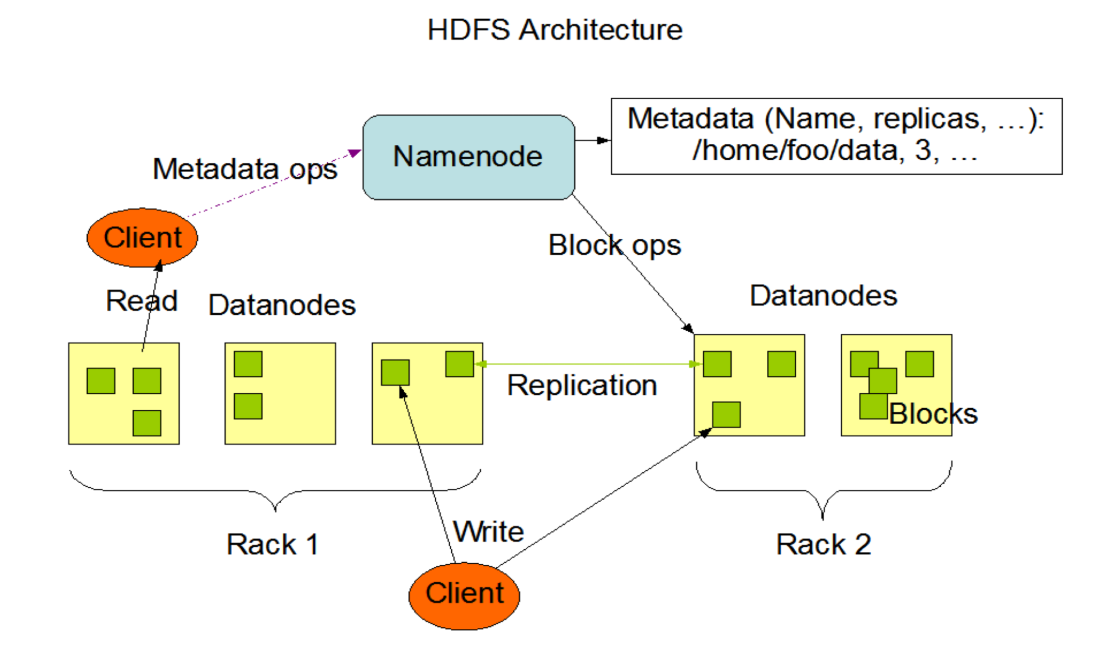
比如一个文件有两个block,hadoop会自动对每个block做三个备份,clinet将文件名提供给NameNode, NameNode对每个block返回三个地址,读取的时候也是先提供文件名给NameNode,然后NameNode返回读取地址。
read & write 流程
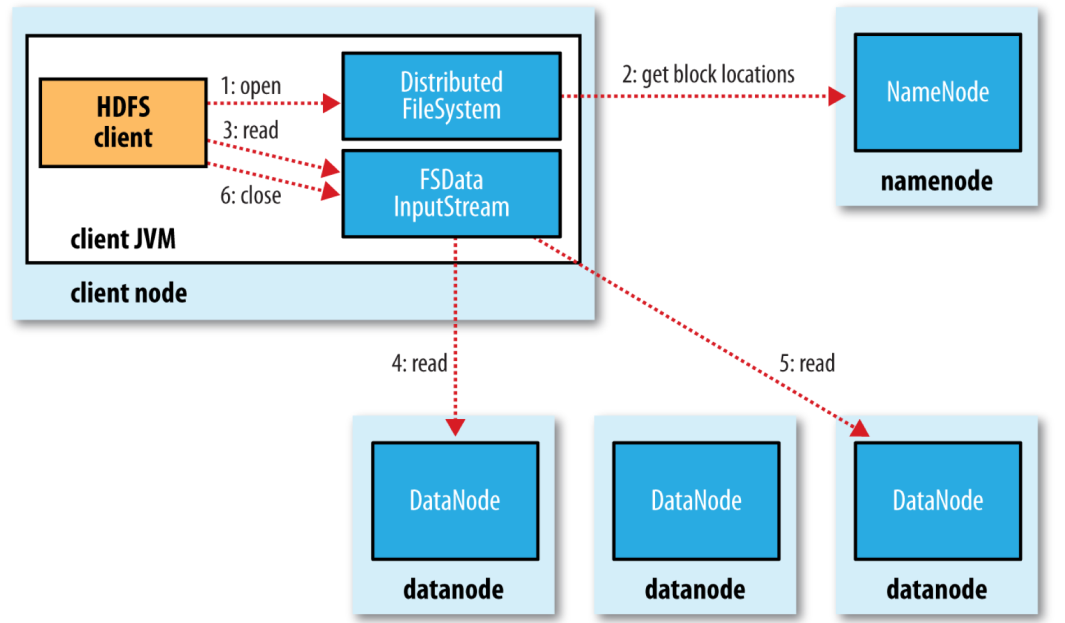
如何选择最近的block?
用di/rj/nk表示在第i个data center的第j个rack(机架)的第k个node
如果在同一个node上,距离为0
在同一个rack(不同node)上,距离为2
在同一个data center(不同rack)上,距离为4
在不同的datacenter中,距离为8
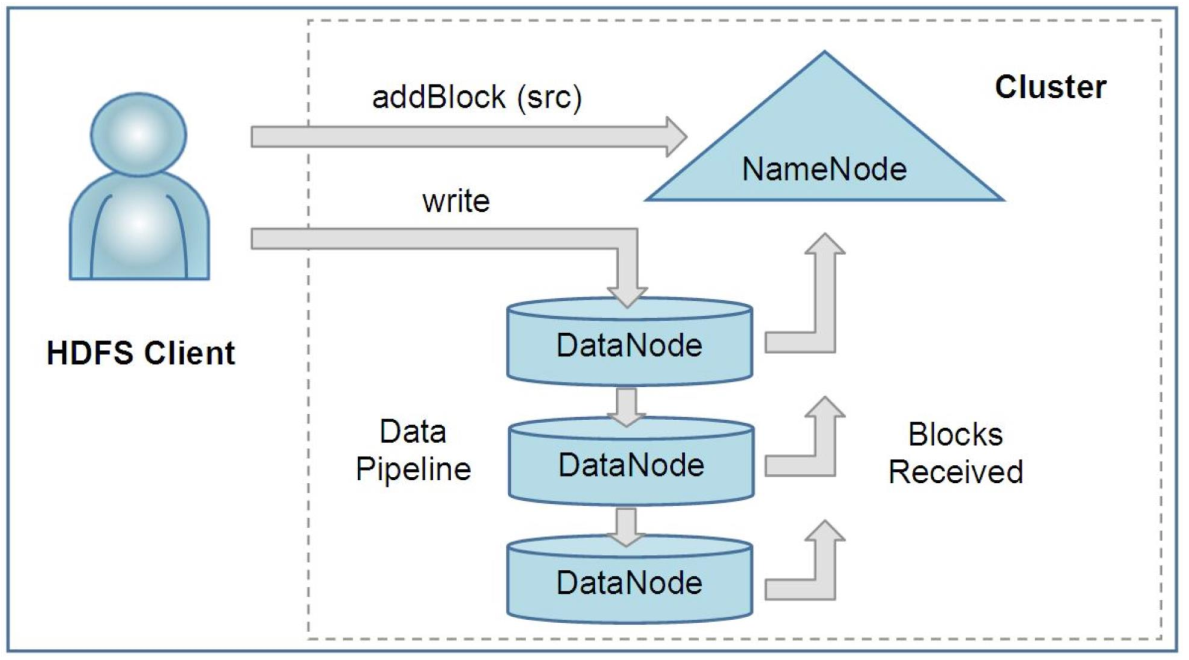
写入的时候使用pipeline,client发送给第一个DataNode,第一个DataNode同时发送给第二个DataNode,以此类推,因此对多个DataNode的写入几乎可以同时完成。
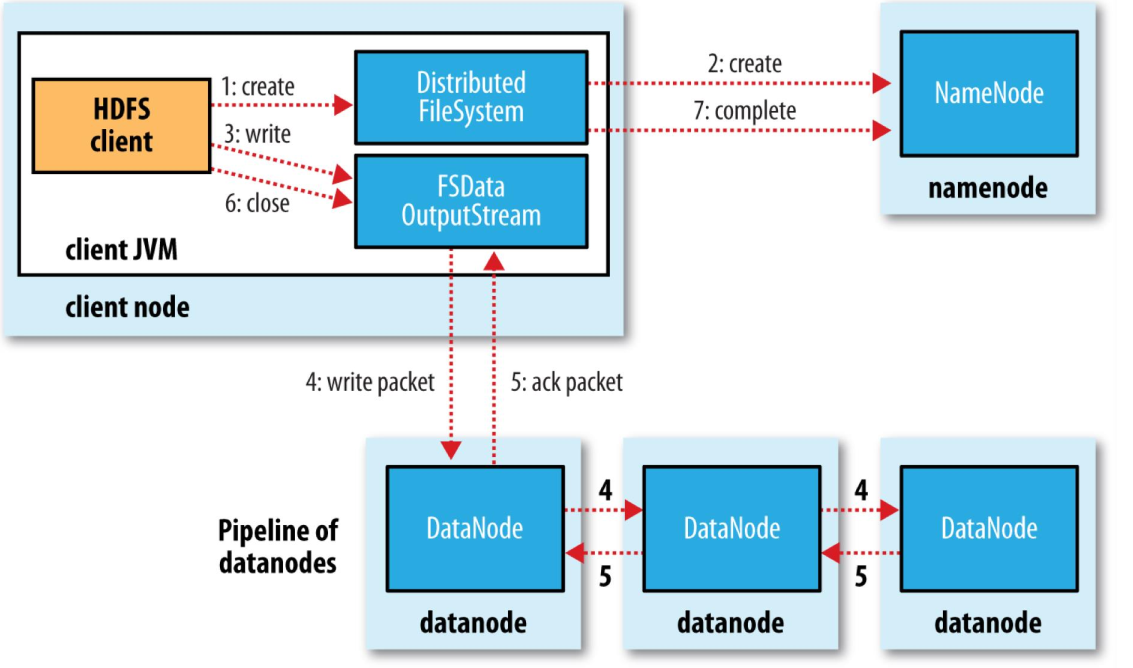
默认的备份逻辑:一份在本地,剩下两份在远程的rack的两个不同节点上
Secondary NameNode
NameNode 负责存储文件系统的元数据(如目录结构、文件权限),记录在内存中的 FsImage(文件系统镜像)和持续追加的 TransactionLog(操作日志)中。随着时间推移,TransactionLog 会变得庞大,导致 NameNode 重启时合并操作耗时过长。Secondary NameNode 定期合并 FsImage 和 TransactionLog,生成新的镜像文件,从而减少 NameNode 的恢复时间。
Standby NameNode
同时维护两个NameNode
-
实时元数据同步
- 共享存储机制:Active NameNode 将操作日志(EditLog)写入共享存储系统(如 JournalNodes 或 NFS),Standby NameNode 持续监听并同步这些日志。
- 内存镜像更新:Standby NameNode 在内存中实时重放 EditLog,保持与 Active NameNode 完全一致的元数据状态(包括文件目录、块位置等)。
-
故障自动切换(Failover)
-
合并元数据(替代 Secondary NameNode)**
- Standby NameNode 定期执行检查点(Checkpoint),将内存中的元数据与 EditLog 合并为新的 FsImage,并写入本地和共享存储。
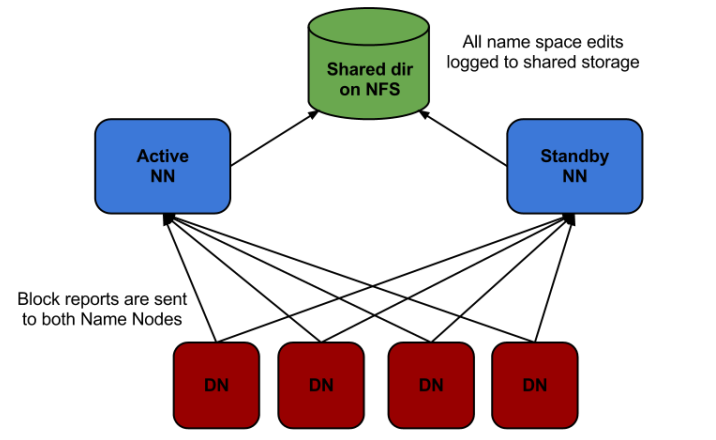
limitations
不支持低延迟/实时响应:每次都要从磁盘读取,很慢
不支持billion级别的数据(所有数据要存metadata在NameNode上,会超出单节点限制)
算法
map combiner设计:WordCount
原版

对于每个单词都生成
(word, 1),在reducer中再做sum
在mapper中使用字典

AssociativeArray就是python中的字典
在mapper中,利用字典,提前做聚合。
问题:如果一个map task里要调用多次map function,该方法的H为局部变量,不同map function之间的结果无法汇总。例如:有一个文本被切分成了两片:hello world hello 和 hello world,该方法只能输出
(hello,2),(world,1)和(hello,1),(world,1)
字典设为全局变量,同一task下的不同map function之间都可以访问

初始化的时候创建H,所有Map function都写入同一个H,在所有map function都结束后执行close以聚合数据
问题:可能需要注意内存管理,因为H可能会过大
in map combining 和 combiner的对比
In-Mapper Combining和Combiner都是为了减少网络传输的数据量
Combiner在Mapper 输出数据后,由框架触发,combiner 1.不影响模型正确性2.combiner是一个可选的优化选项,所以可能被触发0次1次或多次,程序员无法控制;In-Mapper Combining在Mapper中触发。
相比于Combiner,In-Mapper Combining有更快的速度(无io开销),但是需要显示的内存管理,并且在处理顺序比较重要的算法时可能会出问题(因为In-Mapper Combining是按照读取顺序来的,但是combiner是得到所有输出后,进行sort and shuffle后再进行combine操作,因此可以保留顺序)
reducer combiner设计:Mean
错误实现

显然,
mean([1,3])+mean([2,3,4])=5!=mean([1,2,3,3,4])=13/5
使用combiner(错误实现)

使用combiner,combiner中统计mapper中所有结果的sum和count
具体而言,假设数组为mapper 1 的数据为
[1,2,3]则combiner则输出(6,3),从而减少网络传输reducer接收若干
(sum, count)并计算均值但该方法有一个问题,由于combiner可能不执行,所以mapper输出的结果有可能不经过combiner直接到reducer,这样由于数据结构不一样就会出错。
使用combiner(正确实现)

使用in-map combiner

Co-occurrence (bigram) count
统计bigram的词频
原版

问题:
(w,u)的组合的数量为,太大了
Stripes approch
核心思想:使用
w->{u1,u2,...}的数据结构例如:
a->{b:1, c:2, d:5, e:3, f:2}表示(a,b)出现了1次,(a,c)出现了2次,以此类推在aggregate的时候,使用如下方法:
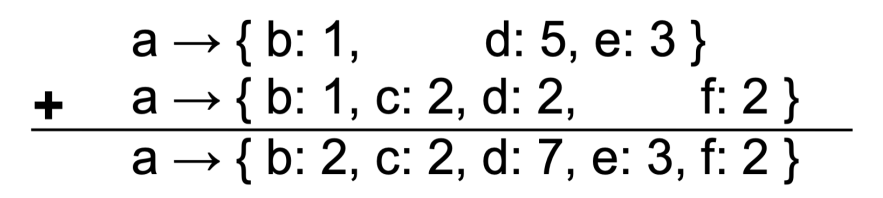

Stripes提升有两个层面,首先,key的数量减少,在排序时减少开销,其次,如果key过于离散,很难遇到聚合的机会,聚合的少,传输的数据就变多了。
Relative frequencies
需要计算
我们需要marginal counts
首先考虑pair approch
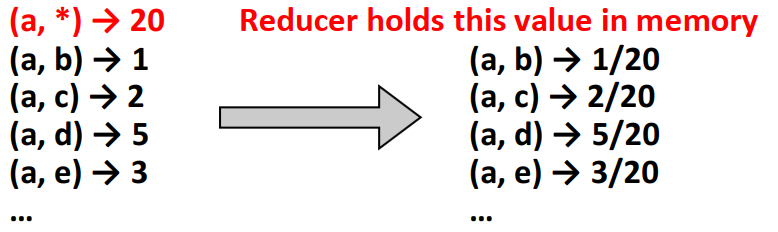
假设reducer以某种顺序处理数据,如果reducer没有拿到marginal counts,那么就要一直等待直到拿到了之后才能进行输出,因此需要确保marginal counts先被拿到

假设以字母表顺序排序,空字符则会在最上面(或者可以自定义排序)。排序会由框架自动完成,这样就可以最先拿到marginal counts。
此外,pair approch需要确保所有比如a开头的全都送到同一个reducer,比如(a,b)和(a,c)等等,否则可能出现(a,b)在一个reducer而(a,*)在另一个reducer。需要通过自定义partitioner来实现。

Secondary Sorting
将value放到key中,让框架自动排序