Gradient Descent
方法1
对于光滑函数f(x),在xk处,希望找到一个方向dk使得函数下降最快。因此考虑
ϕ(α)=f(xk+αdk)
在xk处进行一阶泰勒展开,得:
ϕ(α)=f(xk)+α(∇f(xk))⊤dk+O(α2∥dk∥2)
根据柯西不等式,当α足够小时,取dk=−∇f(xk)会使得函数下降最快。
(∇f(xk))⊤⋅dk≥−∥∇f(xk)∥⋅∥dk∥,当dk=−∇f(xk)时取等。
限制α足够小时为了让O(α2∥dk∥2)足够小,否则解就不一定是dk=−∇f(xk)了。
方法2
对于光滑函数f(x),在xk处,希望在xk的一个邻域求解f(xk)的一阶近似的最小值。具体而言,我们要求解如下问题:
xk+1=xargmins.t. f(xk)+(∇f(xk))⊤(x−xk)∥x−xk∥≤α∥∇f(xk)∥
约束条件只是假设,假设这个邻域的大小是由α∥∇f(xk)∥控制的。
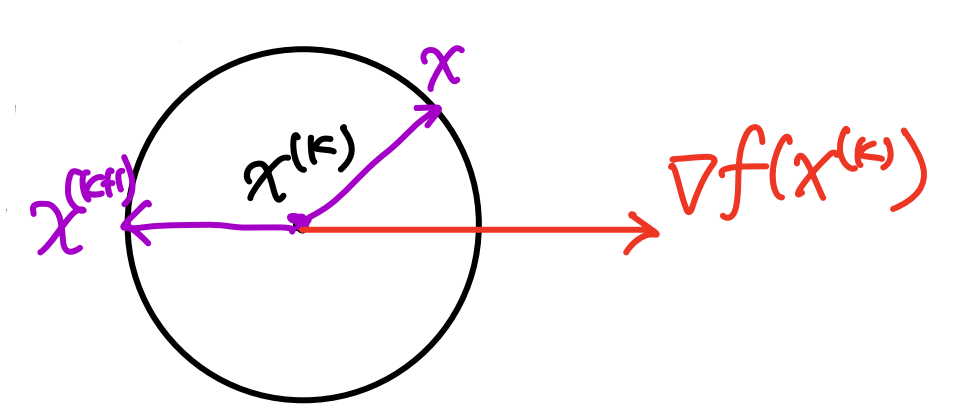
(∇f(xk))⊤(x−xk)=cos(∇f(xk),x−xk)∇f(xk)∥x−xk∥≥−∇f(xk)∥x−xk∥≥−α∇f(xk)2
只要选x−xk=−α∇f(xk)即可满足两个等号。
因此
xk+1=xk−α∇f(xk)
步长选择
固定步长
假设f是L-利普西茨连续的,即
∥∇f(x)−∇f(y)∥≤L∥x−y∥
可以证明
∥∇2f(x)∥≤L
根据二阶泰勒展开,有
f(xk+1)=f(xk)+⟨∇f(xk),xk+1−xk⟩+21⟨xk+1−xk,∇2f(xk)(xk+1−xk)⟩≤f(xk)+⟨∇f(xk),xk+1−xk⟩+2Lxk+1−xk2=f(xk)−α∇f(xk)2+2α2L∇f(xk)2
由于我们希望f(xk+1)<f(xk),求解
−α∇f(xk)2+2α2L∇f(xk)2<0
得:α∈(0,L2)
精确线搜索
αk=α>0argminf(xk−α∇f(xk))
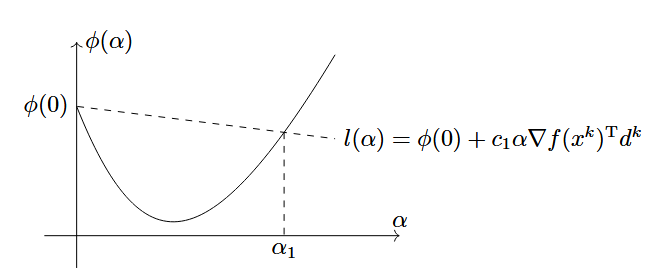
线搜索回退法(Backtracking Line Search)
在非精确线搜索算法中,选取αk需要满足一定的要求,这些要求被称为线搜索准则。Backtracking Line Search算法如下:

Backtracking Line Search先选择一个初始步长,判断是否满足某个先搜索准则,如果满足,则表明我们找到的解是足够好的,可接受的,否则缩小α到γ倍。这里使用的是Armijo准则
f(xk+αdk)⩽f(xk)+c1α∇f(xk)Tdk
加速方法
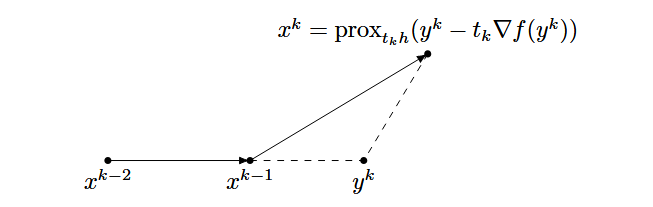
Nesterov法
Nestrov算法由两步组成:第一步沿着前两步的计算方向计算一个新点, 第二步在该新点处做一步近似点梯度迭代:

k−1k−2也可以替换为其它系数,例如可以选择wk−1:
λk=21(1+1+4λk−12),wk−1=λkλk−1−1
Momentum法
vk+1xk+1=βkvk+∇f(xk)=xk−αvk+1
共轭梯度法
在Momentum法的基础上,选取
βk=⟨vk,∇f(xk)−∇f(xk−1)⟩⟨∇f(xk),∇f(xk)−∇f(xk−1)⟩
应用
最小二乘法
x∈Rnmin21∥Ax−b∥2
GD+精确线搜索
xk+1=xk−αkA⊤(Axk−b)
αk=α>0argmin g(α)=α>0argmin 21∥A(xk−αA⊤(Axk−b))−b∥2=α>0argmin 21∥Axk−b∥2−α⟨Axk−b,AA⊤(Axk−b)⟩+2α2∥AA⊤(Axk−b)∥2
假设A的列向量是线性无关的,由于A⊤(Axk−b)=0(不是最优值),因此
g′′(α)=∥AA⊤(Axk−b)∥2>0
根据一阶最优性条件
g′(α)=α∥AA⊤(Axk−b)∥2−⟨Axk−b,AA⊤(Axk−b)⟩=0⇔α=∥AA⊤(Axk−b)∥2⟨Axk−b,AA⊤(Axk−b)⟩=∥AA⊤(Axk−b)∥2∥A⊤(Axk−b)∥2
Steepest Descent Algorithm
for k=0,1,2,⋯gk=A⊤(Axk−b)αk=∥Agk∥2∥gk∥2xk+1=xk−αkgkend
每个循环需要计算2次A的矩阵-向量乘法和1次A⊤的矩阵-向量乘法,但是可以减少到1次A的矩阵-向量乘法和1次A⊤的矩阵-向量乘法。具体而言,要储存gk−1和Agk−1
for k=1,2,3⋯gk=gk−1−αkA⊤(Agk−1)一次A⊤矩阵-向量乘法αk=∥Agk∥2∥gk∥2 一次A矩阵-向量乘法xk+1=xk−αkgkend
将Agk−1写作uk−1
g0=A⊤(Ax0−b)u0=Ag0for k=1,2,3⋯gk=gk−1−αkA⊤uk−1一次A⊤矩阵-向量乘法uk=Agk 一次A矩阵-向量乘法αk=∥uk∥2∥gk∥2xk+1=xk−αkgkend
共轭梯度法
gkpkxk+1=A⊤(Ax−b)=gk+βkpk−1=xk−αkpk
需要求解αk,βk使得f(xk+1)最小。首先由于αk是最优的,因此:
αk=αargming(α)=αargmin21∥A(xk−αpk)−b∥2=αargmin21∥Axk−b∥2−α⟨Axk−b,Apk⟩+2α2∥Apk∥2
根据一阶最优性条件,
g′(α)=α∥Apk∥2−α⟨Axk−b,Apk⟩=0⇔α=∥Apk∥2⟨Axk−b,Apk⟩=∥Apk∥2⟨A⊤(Axk−b),pk⟩=∥Apk∥2⟨gk,pk⟩
αk的这个最优形式可以得到:
⟨gk+1,pk⟩=⟨A⊤(A(xk−αkpk)−b),pk⟩=⟨A⊤A(xk−b)−αkA⊤Apk,pk⟩=⟨gk−αkA⊤Apk,pk⟩=⟨gk,pk⟩−αk⟨A⊤Apk,pk⟩=⟨gk,pk⟩−∥Apk∥2⟨gk,pk⟩⟨Apk,Apk⟩=0
接下来求解βk
(αk,βk)=α,βargminE(α,β)=α,βargminf(xk−α(gk+βpk−1))
denote θ=αβ
E(α,θ)=21A(xk−αgk−θpk−1)−b2=21(b−Axk)+αAgk+θApk−1)2=21(∥b−Axk∥2+α2∥Agk∥2+θ2∥Apk−1∥2+2α⟨b−Axk,Agk⟩+2θ⟨b−Axk,Apk−1⟩+2αθ⟨Agk,Apk−1⟩)
∂θ∂E=θ∥Apk−1∥2+θ⟨b−Axk,Apk−1⟩+2α⟨Agk,Apk−1⟩=θ∥Apk−1∥2+θ⟨A⊤(b−Ax)k,pk−1⟩+α⟨Agk,Apk−1⟩=θ∥Apk−1∥2+α⟨Agk,Apk−1⟩=0
θk=−α∥Apk−1∥2⟨Agk,Apk−1⟩⇔βk=−∥Apk−1∥2⟨Agk,Apk−1⟩
Conjugate Gradient for Least Squares
p−1=0for k=0,1,2,⋯gk=A⊤(Axk−b)βk=−∥Apk−1∥2⟨Agk,Apk−1⟩pk=gk+βkpk−1αk=∥Apk∥2⟨gk,pk⟩xk+1=xk−αkpkend
线性方程组
x∈Rnmins.t. Ax=b A∈Rn×n is SPD
等价于
x∈Rnmin 21x⊤Ax−x⊤b
Steepest Descent(GD+精确线搜索)
xk+1=xk−αk(Axk−b)
其中
αk=α>0argming(α)=α>0argminf(xk−α(Axk−b))=21(xk−α(Axk−b))⊤A(xk−α(Axk−b))−(xk−α(Axk−b))⊤b=21(xk)⊤Axk−(xk)⊤b−α(xk)⊤A(Axk−b)+2α2(Axk−b)⊤A(Axk−b)+α(Axk−b)⊤b
g′(α)=−(xk)⊤A(Axk−b)+α(Axk−b)⊤A(Axk−b)+(Axk−b)⊤b=−((xk)⊤A−b⊤)(Axk−b)+α(Axk−b)⊤A(Axk−b)=0
αk=⟨Axk−b,A(Axk−b)⟩∥Axk−b∥2
Steepest Descent for Linear Equation
for k=0,1,2,⋯gk=Axk−bαk=⟨gk,Agk⟩∥gk∥2xk+1=xk−αkgkend
共轭梯度法
gkpkxk+1=Ax−b=gk+βkpk−1=xk−αkpk
需要求解αk,βk使得f(xk+1)最小。首先由于αk是最优的,类似的,我们有:
αk=argα>0minf(xk−αkpk)=⟨pk,Agk⟩⟨p(k),g(k)⟩
以及⟨gk,pk−1⟩=0。
接下来求解βk
(αk,βk)=α,βargminE(α,β)=α,βargminf(xk−α(gk+βpk−1))
展开,带入⟨gk,pk−1⟩=0,得:
βk=−⟨pk−1,Apk−1⟩⟨gk,Apk−1⟩
p−1=0for k=0,1,2,⋯gk=Axk−bβk=−⟨pk−1,Apk−1⟩⟨gk,Apk−1⟩pk=gk+βkpk−1αk=⟨pk,Agk⟩⟨p(k),g(k)⟩xk+1=xk−αkpkend