封面:Apriori Algorithm in Machine learning | by Palak Bhandari | Medium
问题定义
考虑以下表格,横轴为物品,纵轴为数据,
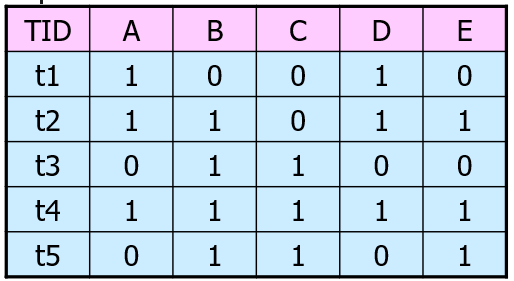
首先定义以下概念:
- item set: 一些物品的组合,例如{B,C}
- rule: 一个item set与另一个物品的关系,例如{B,C}→E表示顾客购买B,C可以推断顾客会购买E
- support: support({B,C}→E)=∣{B,C,E}∣
- confidence: support({B,C}→E)/∣{B,C}∣
我们希望寻找support和confidence大于某个阈值的关联规则
算法
initializek←1Lk={{item1},{item2},⋯,{itemn}}while Lk=∅k←k+1Ck=∅Candidate GenerationJoin step: 将具有相同前缀的项进行合并将(pk−1,a),(pk−1,b)合并为(pk−1,a,b)Ck←{Ck,(pk−1,a,b)}Prune stepfor c∈Ck对于所有c的k−1子集s,如果其不在Lk−1中,则删除cLarge Itemset Generation统计每个itemset的count,然后选择大于threshold的itemsetend while
example
